- videbaks's home page
- Posts
- 2025
- 2024
- 2023
- 2022
- 2021
- 2020
- 2019
- 2018
- December (1)
- November (2)
- October (1)
- September (1)
- August (1)
- July (4)
- April (3)
- March (1)
- February (2)
- January (1)
- 2017
- 2016
- November (1)
- September (2)
- August (2)
- July (1)
- June (1)
- May (1)
- April (1)
- March (1)
- February (1)
- January (1)
- 2015
- 2014
- 2013
- 2012
- 2011
- 2010
- November (3)
- 2009
- My blog
- Post new blog entry
- All blogs
iTPC QA run20
This blog is intended to maintain a log of issues that will be identified as the
run progresses. For initial start the process will be as for run19. See earlier QA blog page
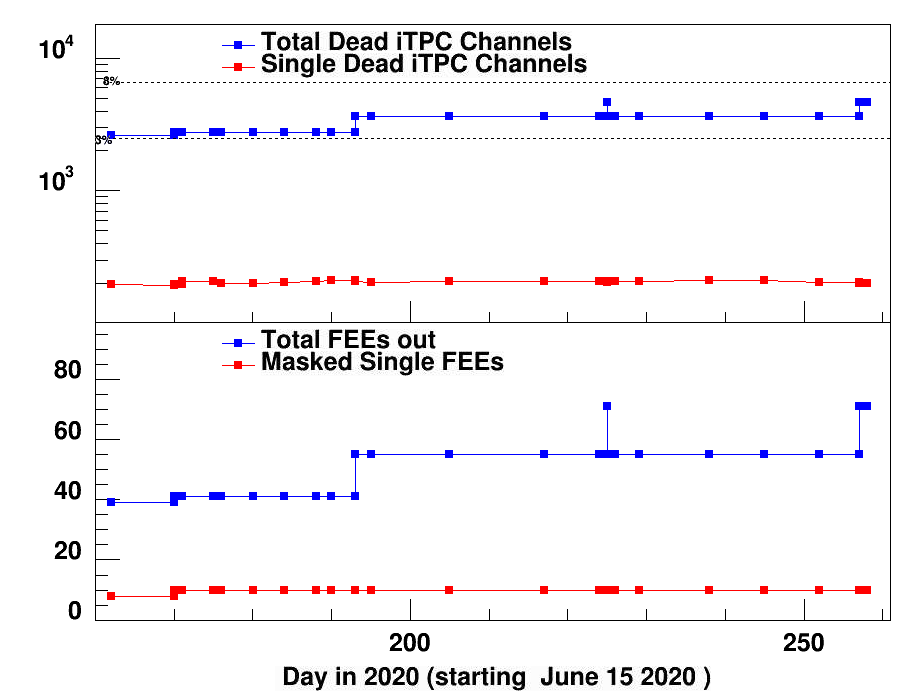
Run20 is in two parts. The top section is the new status with the run starting on June 18. The first part of the curve shows the iTPC status as end of 2020A. Before running two
FEEs had to be masked out namely sector 11-14 and sector 13-27. They were essentially bad even before beam operations had started.
So we start with about , just above 3% , bad channel 2758. Daily comments below summary plot.
Summary Plot updated 9/9142020 (day 258 last point). Last day of run.
At end little more than 5% of iTPC was dead.
In the outer sector 7 RDO's + 1 single FEE ~ 7% lost channels.
The final report of dead FEEs, channels is in this report
Update Feb 2022
The data has been revisited to summarize better what FEEs are masked out
- The datafile for the history plot for Run 2000A is Run20_itpcchannels.txt (here)
- The history of FEE status with runs where this changed is attached as print (pdf) and spread sheet tab2 for run 20
The print also has 2020B (June tru September)
9/13/2020 run 257010. Had to mask out TPC sector 4 itpc RDO -4
9/10/20 18:54
TPX sector 14-6 RDO removed (Jeff). Problems starting pedestal runs.
had to power-down the entire TPX Sector 14 because 1 RDO seems to be asserting the BUSY (Tonko's note)
9/1/2020
End of 9.2 GeV running.
Tonko is looking at sector 13 and 14.
1) TPX Sector 4, RDO 6 should be UNmasked.
2) TPX Sector 13
a) leave the "tpx13" Run Control component out the runs
b) KEEP Sector 13, RDOs 3 & 4 masked
c) UNmask Sector 13, RDO 5
3) TPX Sector 14
a) leave the "tpx14" Run Control component out of the runs
b) KEEP Sector 14, RDOs 3 & 4 masked
c) UNmask Sector 14, RDO 5
Longer version:
Sector 4, RDO #6 seems to be OK now. It had some problems with shorts
on a specific bus (one out of 3) but it looks fine now. If it develops
problems again (it might) I will mask only the offending bus (~1/3 of
the channels). But let's keep our fingers crossed.
Sector 13 & Sector 14 RDOs #3 & #4 seem to have shorts somewhere on
the FEEbus and I can't power the FEEs up. I _hope_ that RDOs #5 will
hold voltage.So far they do. However, they might act up again in which
case we should mask them again.
TPX(24) computer went out for two runs 243.008-009. Powercycle reset fues for computer
Not clear how it happened.
8/26/2020
TPX Sector 4 RDO 6 (most out) was masked out from run 293010. This sector caused issues on 8/7/2020, but has been ok for 3 weeks.
Tonko reports it looks like bus#2 (on RDO) is lost.
8/21/2020
At the QA meeting Lanny reported from fast offline QA thatin sector 18 a partial FEE has nosie. From the ADC plots
it look like about @7 channel has more noise that usual. Lanny says this is probably seen every 1 to 2 days in misc inner sectors
The fastoffline are clusterposition not adc
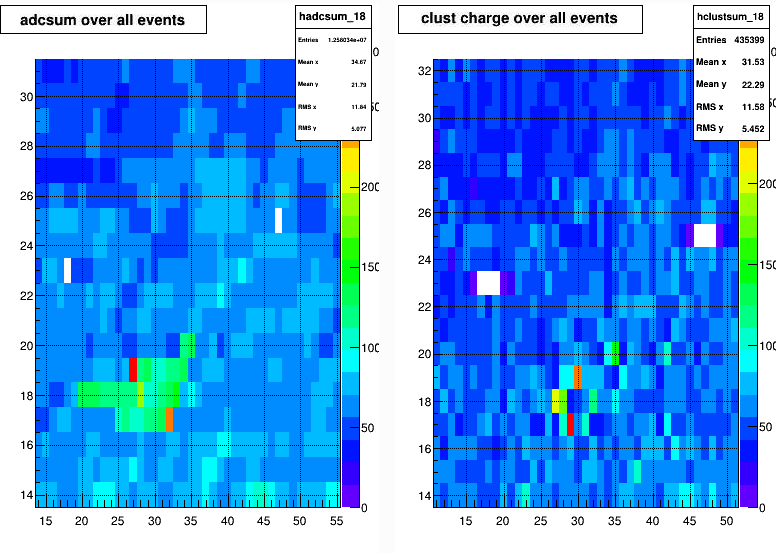
8/12/2020
itpc sector 20 RDO 4 was out for the runs 225007-225021. Issue was the Power Supply
also on sector 20 TPX 3-6 is now out due to PS issue. PC TPX14 is masked out too
8/7/2020
Tonko Checked the 4 masked RDOs in TPX:
S13-3 is an old problem due to trigger and can't be fixed
S14-3 also older and can't be fixed since the RDO doesn't seem to
respond to power. Dead PS perhaps? One can look on a longer access at
the PS end.
S4-6 is new however nothing seems wrong(?). Unmasked but I'll keep an
eye.
S23-6 is new however also nothing seems wrong(?). Unmasked,
Started autore covering when taking data. Tonko looked at log files and believe that it's one (maybe two) bad FEE's
8/3/2020
The areas in sector 14 continues to have different amoint of noise in certain regions. It alwasy around row 15-18 pad 10-14
and lesser on row 27-30 pad ~80. Some times it makes cluster other times not. Likely a FEE problem
This is run 217017 it is clusters.
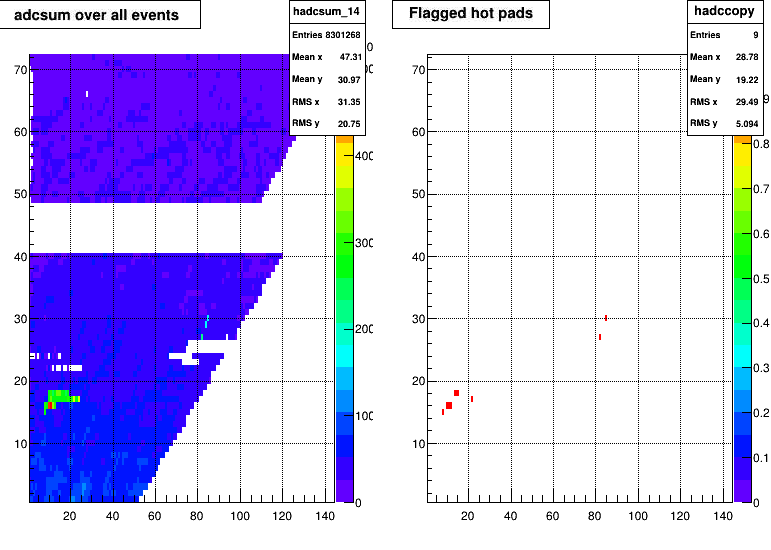
Issues list
On the run 212023 the shiftcrew noticed an issue with excess charge. It did not see in the the analysis of adc files;
jeff's analysis suggested you would see it in zero bias data and that is in fact correct, both adc and clusters
The two plots here are from zero bias runs for sector 13

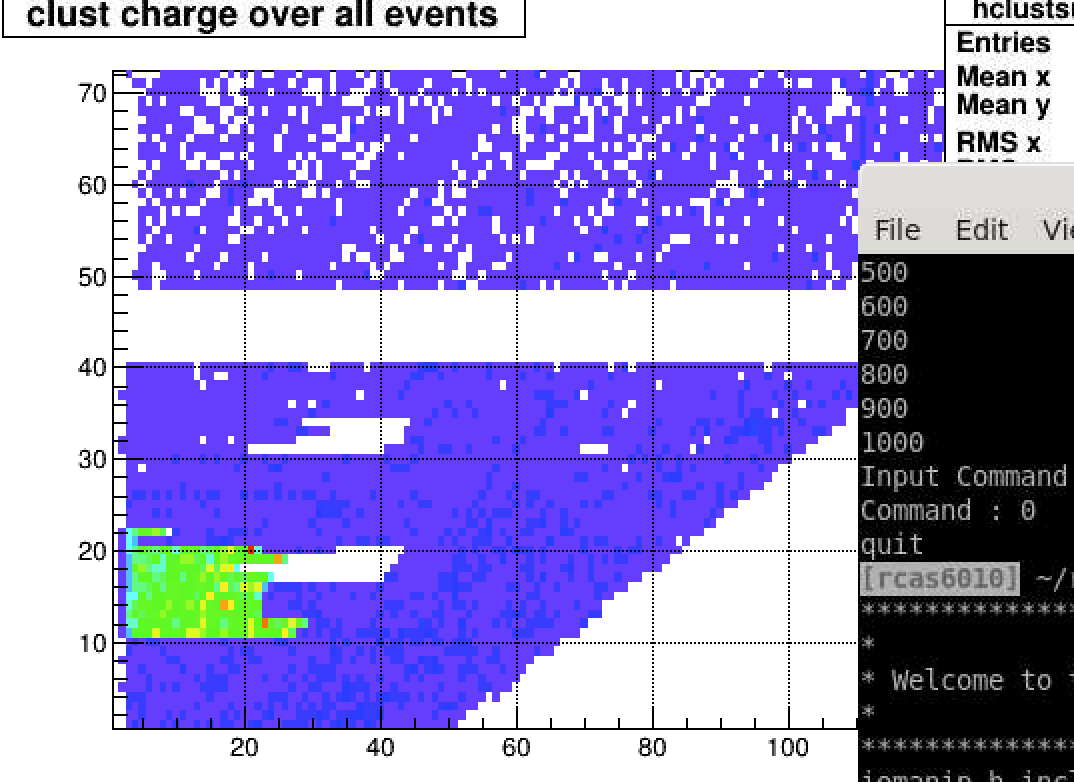
7/29/2020
----------
Run 21212005 - we had to mask out TPC sector 4, RDO 6. We tried restarting it several times but it did not work.
7/28/2020
----------
TPC RDO 23:6 masked out from Run 21210009. Shift tried to restart it twice without success
7/28/2020
---------
data production.
7/27/20
--------
7/25/2020
--------
It seems that these issues with sector 14 are common features. I looked at the runs
206016 to 207008. There is a large number of runs ~8 with hot channels in sector 14 iTPC, and ~11 runs w/o an issues. It seems to come and go
with run restarts, indicating that the startup process with the RDOs is not stable.
For a start
2206016
bad around row,pad (16,20)
206017
ok
206018 ok, 206019 (16,12), 206020 ok, 206021 (~15,15) 206022 *38,62) 205023-206027 ok
206028(17,22) 207001-002 ok
207003 (28-30,80) 207004 ok, 207005 (28-30,~80) 207006-007 ok 207008 (17,12-16)
So certain FEEs seems to reappears with issues. Its so far never more that one area bad, It is inmultiple RDOs.
Clearly issues with the startup - could it be a power suplly issue?
Typical case: a few hot around row 16,17 and then up at row 28-29 (this are not there as often as the other

--------
7/23/2020
For a single run 205015 A single FEE in sector 14 on rows 37-40 around pad 60-70 had more noise than usual. It was not in the preceeding run and disappears in the next.
It also show up in clusters:
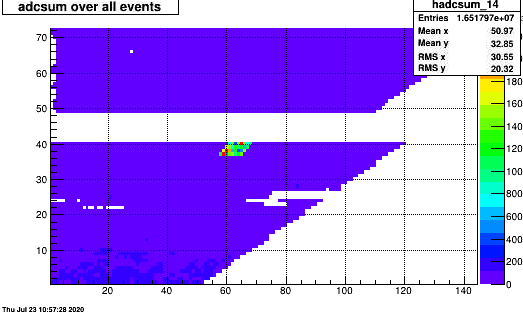
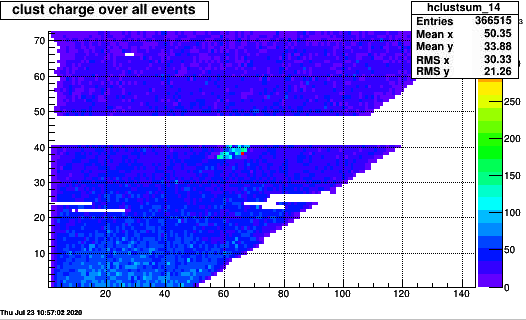
--------
7/11/2020
iTPC 22-2 RDO masked out
the problematic iTPC RDO #2 in Sector 22 from yesterday should stay masked.
The problem is the regulator which supplies the FEE voltages
which seems shot and shows 0V. Nothing we can do without
swapping the RDO so it should stay masked.
Failure start at run 21193006
Last run where it was ok was 21193001. There was a magnettrip about 2 hours before the failure
beam loss at injections. Probably not related.
6/24/2020
run 176011
There is an issue with sector 11 grid leak wall power. We cannot ramp it up to nominal 115 V. It is not going above 95 or so. We asked the beam to be dumped and refilled. David will adjust the threshold for the alarm while we live with this voltage. In parallel Alexei will try to figure out if there is a spare module.
6/22/2020 Tonko masked off several channels in inner sector 7 on FEE 23.
There are still another 3 noisy channels that should be masked off.
They were masked off on 6/26/
6/26/ ~179033
TPX sector 14 RDO 3 was masked out. Seems to be RDO problem.
7/2/2020 Channel 11 for -115V gating grid was reconnected today. It was out for about 2 weeks,
7/4/2020 TPX HV 11-5 was out for a set of runs due to communication problems
David looked into this. The problem seems to be understood. I think we need some action how to fix the DB values for
sector 11-5 for the runs we know from QA are down. See e-mail below
t the Thursday QA meeting the behaviour of sector 11-5 (HV) was brought up. After investigations we have learned that the issue is present in 21176027-11177012 due to non communication with the Caen HV IOC. The DB entries for 11-5 should be zeroed for these runs. David with look at alternative mechanism to see that we do not miss HV trips.
-------- Original Message --------
Subject: Re: CAEn HV on day 176 sector 11-5
Date: 2020-07-03 20:38
From: David Tlustý <tlusty@gmail.com>
To: videbaek <videbaek@bnl.gov>
Hi Flemming,
There seems to be loss of communication with the TPC CAEN HV
power supply. There could have been a trip on that particular channel,
but the alarm didn't register it. All the anodes between June 24th ~20:30
and June 25th ~11:20 show flat values. I remember now that similar
thing happened back in February. So it looks like there was a trip, but
because the CAEN IOC was not updating values it got unnoticed
until the next day when shift crews ramped down anodes to 0
to take pedestals. The problem is here that the IOC runs on
the CAEN power supply and not on one of our computers on
the starp network. I have to think about it and come with some
solution. Make some IOC that will check the response of the CAEN
values and it is constant it will alert us that the values are not being updated.
The grid leak channel has probably nothing to do with it. I put
the alarm back on it couple days ago already.
Best,
David
7/5/2020
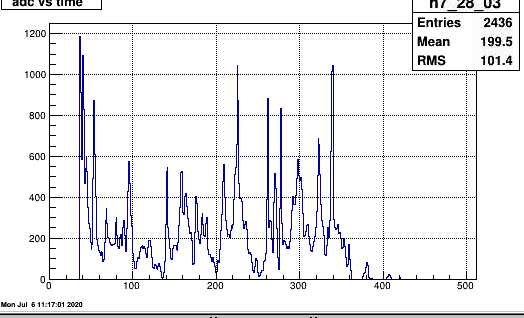
It seems that another channel in a FEE has become very noisy. This is sector 7 row 83 - pad 03 (three). It is first observed in run184006 after a long downtime with magnet trip, and many thunderstorms..
The plot shows the adc time spectrum for row (28,03) and (28,04) for 100 events. So the average noise is ~20 counts per timebin/event
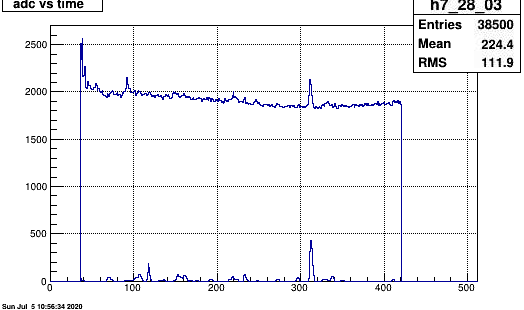
7/5/2020 This hot channel was fixed (somehow) after start of 187015 and the next run 016 which had no hot channel. Possible RDO powercycle?
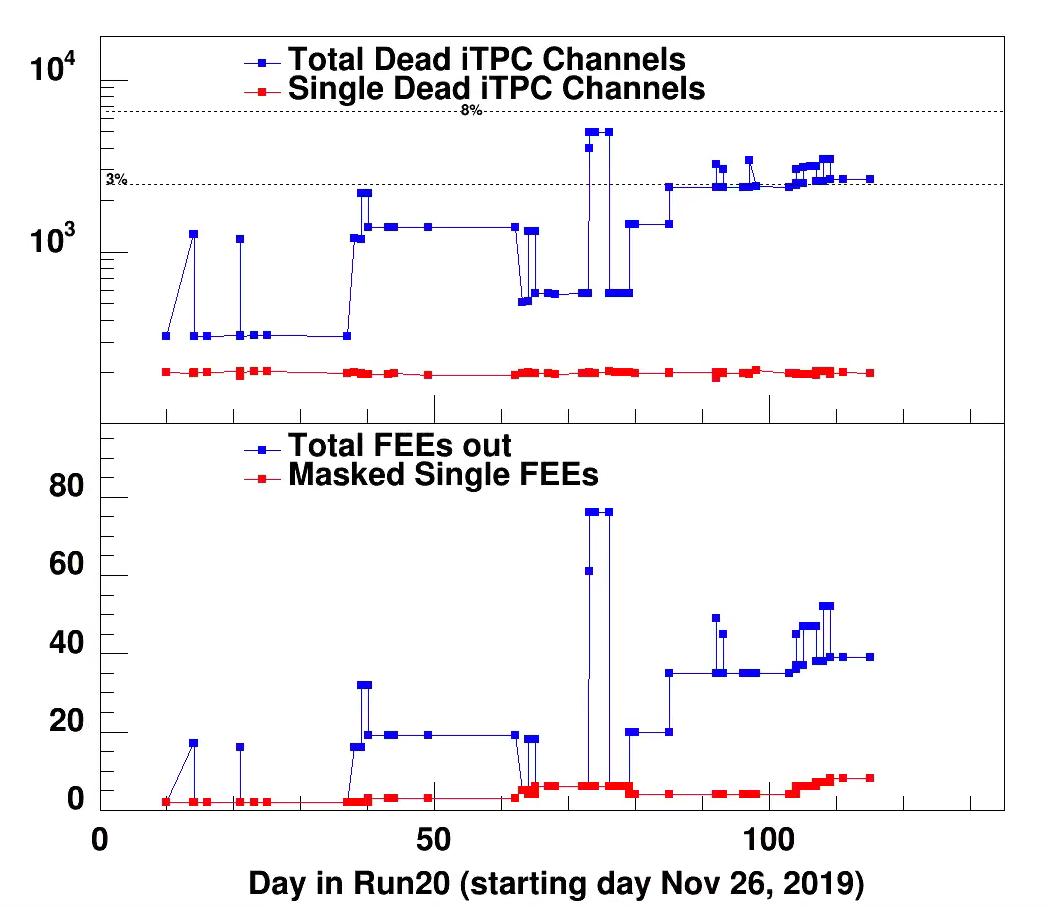
3/20 End of run-20 No more issues; Updated final plot; Just note the last ~8 days of 2019 hade issues with sector 12, on/off
not properly documented.
For final report I also added Tonko's running document on TPC work and repairs
3/13 sector 3-2 was masked out and 073038 and fixed with FEE#1422 in the sector on 3/14 after run 074016 (15 last one masked out)
3/12 sector 18-1 was fixed a single FEE was masked out (had gotten unstable)
3/10/2020 from 070014 sector 18-1 RDO masked out.
Tonko reports (3/11) it's a single channel on a FEE. He will fix it on 3/12
3/9/2020 sector 14 rdo 4 one FEE masked out (port9)
sector 21 RDO-1 port#6 FEE masked out
Day 058027
There was a single run with a hot FEE (#3 on sector 9) it went away in the following new run.
Extra cluster but none on track, and roughly half of the FEE seen with ADCs. Distributed over all time bins.
s
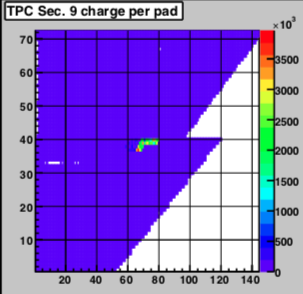
3/2/20-3/3/20 sector9-4 was out from ~ noon to 2am next day. Eprom reload; high background
2/27 sector 1-RDO-1 had eprom reloaded
was out for just one run 058019
2/26 sector 23-RDO-3 was out for about 5 hours due to rad damaged eProm
ok again for 057019..
Status update Thursday 2/20 from Tonko
) iS20-3 is known. The board needs to "warm up" for 10 minutes
after power-up so this problem happens after every access *sigh*.
Repeated power-cycling makes the problem worse, unfortunately.
I can perhaps change the message for that board specifically. I'll see.
Or we add this comment to the board in the Control Room :-)
2) iS10-4 also known power problems. It will need to have 2 more FEEs disabled.
Better 2 more FEEs than the entire RDO. Let me think which FEEs.
3) TPX S13-3 is also a know problem and nothing we can do. Leave it masked.
2/13
2/11 Tonko managed to resurrect sector 12 by disabling effect of bit 8 on tcd cable. Required running old
software to recompile. Seem to work well.
2/7/20
Late evening sector 20-3 (itpc) started with repeated auto recycling it was disabled
starting run 03833. There is presently many RDO's diaabled
All of sector 12
Sector 20- RDO 3
single itpc FEEs in 21-1, 13-2, 10-4 (2) and 8-2 (2)
2/7/20
The whole sector 12 was disabled due to TCD (trigger cable issue)
After the access run 21038013 Tonko reported
The problem is under the poletip somewhere and nothing
we tried to do made it go away.
The problem is 1 single bit of the TCD trigger cable which
was always "0" in December (so we got around it by
using a different bit as the "trigger" pulse) but now it
is always a "1" which causes the RDOs to be "triggered"
all the time. There seems to be some sort of cable
disconnect or receiver chip malfunction.
However, I can reprogram the iTPC firmware to simply
ignore this bit on that Sector and it should work OK.
Unfortunately, I can't do this for the TPX (outer sector)
because I don't have the firmware tools anymore (15 years old).
So for the weekend we should continue as we are, without
Sector 12 altogether. I'm assuming I won't have ~2hrs alone with
the system to play with and get it all hacked-up and somewhat
recovered.
1/29/2020
sector 8-2 could not recycle; fixed by disabling one FEE
Runs w/o FEE are 21029027 to 21030010
1/28/2020
Sector 10-4 summary from Tonko's tpc log
1/09/20
The sector 10-4 only worked for a short time (few hours)
runs 008023-008034 (few cosmic runs + one data run
1/08/2020
Tonko:
Bob Scheetz found a bad fuse on the power supply and
exchanged it.
iTPC S10-4 is now working and also unmasked.
One fuse was blown, but others looked flacky, currents are now stable.
last run where bad was 21008016
1/06/2020
Tonko:
I looked at the failed & masked iTPC RDO iS10-4 in detail.
The problem is with the power, possibly the power supply. We would need an access to take a better look at the PS to see where the problem lies.
1/05/2010 fixed by run 21005019
msg from Tonko
please unmask ITPC Sector 13, RDO 2 on the next run.
A FEE died and I masked it out.
1/04/2020 sector10 itpc RDO 4
caused problems in 21004005 and then in 007 with 7 auto eboot during run, after which it was masked out.
1/03/2020
sector 13-2 out as of run 21003011
sun 12/22/19
For the runs between 2:44 and 8:15 today (20356005-20356018), there is some chance that the data from sector 12 is wrong (comes from a different event). During this time we were running with 4095 tokens, but half of them were indistinguishable to sector 12. There were many errors / overruns during these runs, and it is difficult to know whether the events that were built contain data from the correct token or from a indistinguishable token.
12/20/2019 sector 12 issue
Tonko msg:-
The entire Sector 12 sees bad/corrupt trigger data.
But the clock on that same cable is OK so it's not a total cable disconnect.
The cables get fanned out to 24 sectors in one board/system
(called "TDBm") which is my prime suspect right now.
1) I masked out the TPX RDOs which end up being readout
on a PC called "tpx30" so we can include "tpx30" in the runs.
This will also re-enable 2 outmost RDOs from the adjacent sector 11.
2) I powercycled the TDBm fanout but this made no difference.
3) Next suspect is the cable connections on the fanout,
perhaps the connector/cable got dislodged (it happened).
But for this I need tech help (Bob Scheetz preferably).
I sent him email and I'll call him in the morning.
4) If it is not a simple bad connection it could be a dead
PECL driver chip in that fanout (it also happened) so
we need to change it or swap in a spare. This also needs
to wait until the morning.
5) In the worst case it can be some sort of cable disconnect
at the poletip so, well, you know what that means :-).
But at this stage I find it unlikely.
For now please leave the Run Control components "tpx12"
and "itpc12" out of the runs.
-- report from shift earlier
We were trying to take a pedestal_tcd_only data after the LEReC was done. However, it shown that trigger is 100% from the DAQ monitoring and the number of event
token by detectors are all 0. We called DAQ expert Jeff. He took the control and did some tests, he mentioned that the TPC sector 12
(TPX 12, 30 and iTPC 12) are busy during the data token. There sectors will make it hard to take any data, also he do not think this is a software issue.
Currently, the suggestion is we need to mask out these sectors from run control during tonight’s runs.
353035 sector 12 and 2 RDO from 11 (TPX computer 30)
354003 - 354006 all of 12 out (planned to be fixed at 2pm Friday)
12/18/19 Shift e-log
Run 20352010 - TPC inter Cage 1 current red alert after beam dump.
Run 20352016 - TPX died, TPX28 masked out, try restarting the run
Run 20352018 - 6:00 am production_11p5GeV_2020, TRG+DAQ+TPX+iTPC+BTOW+TOF+GMT+L4, include TPX28
12/17/19
Run 20351004 - We managed to start the run by clicking in and out iTPC, and this run contains ETOF, BBC 100kHz, minbias 160 Hz
production_11p5GeV_2020, TRG+DAQ+TPX+iTPC+BTOW+TOF+ETOF+GMT+L4
------------------------------------
Tonko: Nah, clicking in/out doesn't do anything. But I fixed the issue in the background: power-cycled RDO iTPC iS22-4 and restarted DAQ.
12/10/19 Flemming
I started up my QA test of file. Overall things look good. The statistics is for iinner sectors only. The particular run 344017 had Sector 20 RDO-3 masked out (15 FEE) . Apart from that there are
2 single FEEs masked out S12-FEE-47 S8 FEE-33. There are a total of 198 single bad channels with a total of 1259.
I noted that the charge (ADC) plot for TPX sector 4 seems to have an even-odd issue. This is not seen in the JEVP plot since these have a binning of 4.
Only sector 4 shows this. Will check to see what part of the sector shows this. False alarm - it all comes from a single hot pad in sector 4 TPX
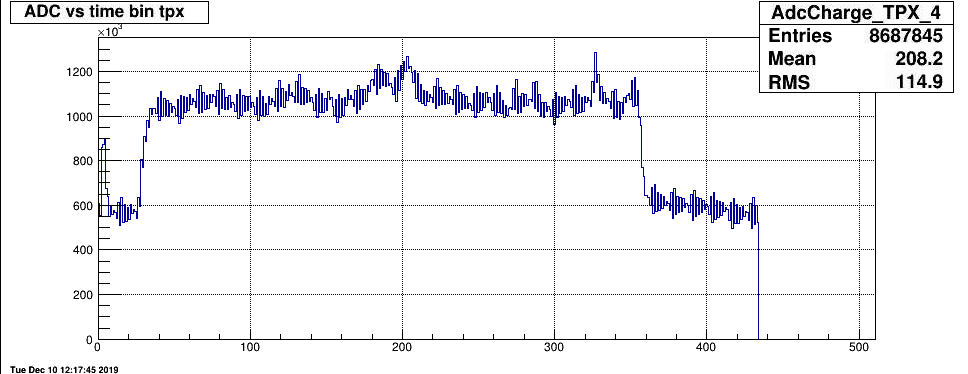
12/10/19
7:43 tonko
Unmasked iTPC S20-3. The problem is in the trigger interface of the board and is intermittent. There seems to be a bad connection and I think is is due to the temperature and once the board warms up it starts to work fine. Now that we are in relatively stable run conditions I'd like to see how it behaves over the course of a day, e.g.
12/8/2019
Run 20342030 - Upon instruction from Tonko, we rebooted the iTPC DAQ computer. The iTPC20 in the component tree was back, and we unmasked iTPC sector 20 RDO3. But we couldn't start the run (the run was in configuring mode and iTPC20 was waiting for several minutes). We did another reboot of the DAQ computer. And after that, we noticed the iTPC20 RDO3 LED light shows still grey, we powercycled the FEE on SC. The run eventually got started.
If later on this iTPC sector 20 RDO3 causes problem, mask it out from RC and leave a note in SL.
It is now masked off (Rdo 3)
12/4/2019
The pole tip was opened and the cable was replaced for 11.5 PSU . It is now operational
Tested the 'bad cable' Bob Scheetz reported
So after improving my test procedure, I do see a problem with that cable we removed. When I use a pigtail connector with the meter clipped to the leads and make a fully latched connection I don’t have conductivity , I need to put side pressure on the connector to make contact, need to explore this more. Some of my other spares have similar problems. Not Good.
12/2/2019 (11:15 Mike C.
Replaced two fuses in S11.5 PSU, reconnected cable. Left S11.5 PSU "OFF", one conductor open in cable will cause fuses to blow until cable is replaced.
12/2/2019
6:14 (tonko note)
1) itpc20-3 again has problems with the TCD interface. Powercycled and now it's OK. Unmasked. However, this will probably happen again. Let's see.
2) itpc21-1 dead FEE on port #8. Doesn't look recoverable. Masked the particular FEE and unmasked the RDO.
11/29/2019 4:34 (tonko from e-log)
Some fixes to TPX/iTPC electronics:
1) itpc20-3 has issues with token overruns, oddly. Now it works so I unmasked it but I will keep an eye on it because the problem will likely return.
2) tpx05-3 masked 2 FEEs on a bad RDO bus. Magnet related? RDO unmasked.
3) tpx17-3 masked 2 FEEs on a bad RDO bus. Magnet related? RDO unmasked.
4) itpc08-2 masked 1 FEE. The FEE seems to come and go causing too many recoveries. It looks like it's on the RDO end (port #6) because we already changed that FEE.
5) tpx11-4 and tpx11-5 are still down due to a power supply failure. Need to wait for Monday for e.g. Mike to take a look and swap it.
run progresses. For initial start the process will be as for run19. See earlier QA blog page
Run20 is in two parts. The top section is the new status with the run starting on June 18. The first part of the curve shows the iTPC status as end of 2020A. Before running two
FEEs had to be masked out namely sector 11-14 and sector 13-27. They were essentially bad even before beam operations had started.
So we start with about , just above 3% , bad channel 2758. Daily comments below summary plot.
Summary Plot updated 9/9142020 (day 258 last point). Last day of run.
At end little more than 5% of iTPC was dead.
In the outer sector 7 RDO's + 1 single FEE ~ 7% lost channels.
The final report of dead FEEs, channels is in this report
Update Feb 2022
The data has been revisited to summarize better what FEEs are masked out
- The datafile for the history plot for Run 2000A is Run20_itpcchannels.txt (here)
- The history of FEE status with runs where this changed is attached as print (pdf) and spread sheet tab2 for run 20
The print also has 2020B (June tru September)
9/13/2020 run 257010. Had to mask out TPC sector 4 itpc RDO -4
9/10/20 18:54
TPX sector 14-6 RDO removed (Jeff). Problems starting pedestal runs.
had to power-down the entire TPX Sector 14 because 1 RDO seems to be asserting the BUSY (Tonko's note)
9/1/2020
End of 9.2 GeV running.
Tonko is looking at sector 13 and 14.
1) TPX Sector 4, RDO 6 should be UNmasked.
2) TPX Sector 13
a) leave the "tpx13" Run Control component out the runs
b) KEEP Sector 13, RDOs 3 & 4 masked
c) UNmask Sector 13, RDO 5
3) TPX Sector 14
a) leave the "tpx14" Run Control component out of the runs
b) KEEP Sector 14, RDOs 3 & 4 masked
c) UNmask Sector 14, RDO 5
Longer version:
Sector 4, RDO #6 seems to be OK now. It had some problems with shorts
on a specific bus (one out of 3) but it looks fine now. If it develops
problems again (it might) I will mask only the offending bus (~1/3 of
the channels). But let's keep our fingers crossed.
Sector 13 & Sector 14 RDOs #3 & #4 seem to have shorts somewhere on
the FEEbus and I can't power the FEEs up. I _hope_ that RDOs #5 will
hold voltage.So far they do. However, they might act up again in which
case we should mask them again.
TPX(24) computer went out for two runs 243.008-009. Powercycle reset fues for computer
Not clear how it happened.
8/26/2020
TPX Sector 4 RDO 6 (most out) was masked out from run 293010. This sector caused issues on 8/7/2020, but has been ok for 3 weeks.
Tonko reports it looks like bus#2 (on RDO) is lost.
8/21/2020
At the QA meeting Lanny reported from fast offline QA thatin sector 18 a partial FEE has nosie. From the ADC plots
it look like about @7 channel has more noise that usual. Lanny says this is probably seen every 1 to 2 days in misc inner sectors
The fastoffline are clusterposition not adc
8/12/2020
itpc sector 20 RDO 4 was out for the runs 225007-225021. Issue was the Power Supply
also on sector 20 TPX 3-6 is now out due to PS issue. PC TPX14 is masked out too
8/7/2020
Tonko Checked the 4 masked RDOs in TPX:
S13-3 is an old problem due to trigger and can't be fixed
S14-3 also older and can't be fixed since the RDO doesn't seem to
respond to power. Dead PS perhaps? One can look on a longer access at
the PS end.
S4-6 is new however nothing seems wrong(?). Unmasked but I'll keep an
eye.
S23-6 is new however also nothing seems wrong(?). Unmasked,
Started autore covering when taking data. Tonko looked at log files and believe that it's one (maybe two) bad FEE's
8/3/2020
The areas in sector 14 continues to have different amoint of noise in certain regions. It alwasy around row 15-18 pad 10-14
and lesser on row 27-30 pad ~80. Some times it makes cluster other times not. Likely a FEE problem
This is run 217017 it is clusters.
Issues list
On the run 212023 the shiftcrew noticed an issue with excess charge. It did not see in the the analysis of adc files;
jeff's analysis suggested you would see it in zero bias data and that is in fact correct, both adc and clusters
The two plots here are from zero bias runs for sector 13
7/29/2020
----------
Run 21212005 - we had to mask out TPC sector 4, RDO 6. We tried restarting it several times but it did not work.
7/28/2020
----------
TPC RDO 23:6 masked out from Run 21210009. Shift tried to restart it twice without success
7/28/2020
---------
Run 21209030 TPC sector 14 hot channels near Row 15 pad 15
Run 21210002 in (row, pad) = (17, 24);
Run 21210003 in (row, pad) = (16, 8);
Run 21210010 in (row, pad) = (17, 24), (29, 80-85);
Run 21210013 in (row, pad) = (15, 1-2);
Run 21210014 in (row, pad) = (18, 18);
Run 21210015 TPC Sec. 14 hot spots (row, pad)-(16,8),(17,15)
data production.
7/27/20
--------
Run 21208037 TPC Sector 14, a hot spot at row 49 pad 85
Run 21208038 TPC sector 14 hot spot Row 53 pad ~70
Run 21209001 - TPC Sector 14 pad 20 row 18
Run 21209010 - Hot spot in TPC charge per pad at section 14, pad 10 to 15
Run 21209013 - Three hot spots in iTPC sector 14:row 16 pad 12, row 17 pad 13, row 17 pad 18
7/25/2020
--------
It seems that these issues with sector 14 are common features. I looked at the runs
206016 to 207008. There is a large number of runs ~8 with hot channels in sector 14 iTPC, and ~11 runs w/o an issues. It seems to come and go
with run restarts, indicating that the startup process with the RDOs is not stable.
For a start
2206016
bad around row,pad (16,20)
206017
ok
206018 ok, 206019 (16,12), 206020 ok, 206021 (~15,15) 206022 *38,62) 205023-206027 ok
206028(17,22) 207001-002 ok
207003 (28-30,80) 207004 ok, 207005 (28-30,~80) 207006-007 ok 207008 (17,12-16)
So certain FEEs seems to reappears with issues. Its so far never more that one area bad, It is inmultiple RDOs.
Clearly issues with the startup - could it be a power suplly issue?
Typical case: a few hot around row 16,17 and then up at row 28-29 (this are not there as often as the other
--------
7/23/2020
For a single run 205015 A single FEE in sector 14 on rows 37-40 around pad 60-70 had more noise than usual. It was not in the preceeding run and disappears in the next.
It also show up in clusters:
--------
7/11/2020
iTPC 22-2 RDO masked out
the problematic iTPC RDO #2 in Sector 22 from yesterday should stay masked.
The problem is the regulator which supplies the FEE voltages
which seems shot and shows 0V. Nothing we can do without
swapping the RDO so it should stay masked.
Failure start at run 21193006
Last run where it was ok was 21193001. There was a magnettrip about 2 hours before the failure
beam loss at injections. Probably not related.
6/24/2020
run 176011
There is an issue with sector 11 grid leak wall power. We cannot ramp it up to nominal 115 V. It is not going above 95 or so. We asked the beam to be dumped and refilled. David will adjust the threshold for the alarm while we live with this voltage. In parallel Alexei will try to figure out if there is a spare module.
6/22/2020 Tonko masked off several channels in inner sector 7 on FEE 23.
There are still another 3 noisy channels that should be masked off.
They were masked off on 6/26/
6/26/ ~179033
TPX sector 14 RDO 3 was masked out. Seems to be RDO problem.
7/2/2020 Channel 11 for -115V gating grid was reconnected today. It was out for about 2 weeks,
7/4/2020 TPX HV 11-5 was out for a set of runs due to communication problems
David looked into this. The problem seems to be understood. I think we need some action how to fix the DB values for
sector 11-5 for the runs we know from QA are down. See e-mail below
t the Thursday QA meeting the behaviour of sector 11-5 (HV) was brought up. After investigations we have learned that the issue is present in 21176027-11177012 due to non communication with the Caen HV IOC. The DB entries for 11-5 should be zeroed for these runs. David with look at alternative mechanism to see that we do not miss HV trips.
-------- Original Message --------
Subject: Re: CAEn HV on day 176 sector 11-5
Date: 2020-07-03 20:38
From: David Tlustý <tlusty@gmail.com>
To: videbaek <videbaek@bnl.gov>
Hi Flemming,
There seems to be loss of communication with the TPC CAEN HV
power supply. There could have been a trip on that particular channel,
but the alarm didn't register it. All the anodes between June 24th ~20:30
and June 25th ~11:20 show flat values. I remember now that similar
thing happened back in February. So it looks like there was a trip, but
because the CAEN IOC was not updating values it got unnoticed
until the next day when shift crews ramped down anodes to 0
to take pedestals. The problem is here that the IOC runs on
the CAEN power supply and not on one of our computers on
the starp network. I have to think about it and come with some
solution. Make some IOC that will check the response of the CAEN
values and it is constant it will alert us that the values are not being updated.
The grid leak channel has probably nothing to do with it. I put
the alarm back on it couple days ago already.
Best,
David
7/5/2020
It seems that another channel in a FEE has become very noisy. This is sector 7 row 83 - pad 03 (three). It is first observed in run184006 after a long downtime with magnet trip, and many thunderstorms..
The plot shows the adc time spectrum for row (28,03) and (28,04) for 100 events. So the average noise is ~20 counts per timebin/event
7/5/2020 This hot channel was fixed (somehow) after start of 187015 and the next run 016 which had no hot channel. Possible RDO powercycle?
3/20 End of run-20 No more issues; Updated final plot; Just note the last ~8 days of 2019 hade issues with sector 12, on/off
not properly documented.
For final report I also added Tonko's running document on TPC work and repairs
3/13 sector 3-2 was masked out and 073038 and fixed with FEE#1422 in the sector on 3/14 after run 074016 (15 last one masked out)
3/12 sector 18-1 was fixed a single FEE was masked out (had gotten unstable)
3/10/2020 from 070014 sector 18-1 RDO masked out.
Tonko reports (3/11) it's a single channel on a FEE. He will fix it on 3/12
3/9/2020 sector 14 rdo 4 one FEE masked out (port9)
sector 21 RDO-1 port#6 FEE masked out
Day 058027
There was a single run with a hot FEE (#3 on sector 9) it went away in the following new run.
Extra cluster but none on track, and roughly half of the FEE seen with ADCs. Distributed over all time bins.
s
3/2/20-3/3/20 sector9-4 was out from ~ noon to 2am next day. Eprom reload; high background
2/27 sector 1-RDO-1 had eprom reloaded
was out for just one run 058019
2/26 sector 23-RDO-3 was out for about 5 hours due to rad damaged eProm
ok again for 057019..
Status update Thursday 2/20 from Tonko
) iS20-3 is known. The board needs to "warm up" for 10 minutes
after power-up so this problem happens after every access *sigh*.
Repeated power-cycling makes the problem worse, unfortunately.
I can perhaps change the message for that board specifically. I'll see.
Or we add this comment to the board in the Control Room :-)
2) iS10-4 also known power problems. It will need to have 2 more FEEs disabled.
Better 2 more FEEs than the entire RDO. Let me think which FEEs.
3) TPX S13-3 is also a know problem and nothing we can do. Leave it masked.
2/13
-
itpc10-4 power problems seem to be increasing, it seems that it can’t hold power with only the 2 FEEs masked (Feb 13)
-
kill another 2 FEEs?
this happened at run 044025-26 disabled from 029 on - no fakes.
-
2/11 Tonko managed to resurrect sector 12 by disabling effect of bit 8 on tcd cable. Required running old
software to recompile. Seem to work well.
2/7/20
Late evening sector 20-3 (itpc) started with repeated auto recycling it was disabled
starting run 03833. There is presently many RDO's diaabled
All of sector 12
Sector 20- RDO 3
single itpc FEEs in 21-1, 13-2, 10-4 (2) and 8-2 (2)
2/7/20
The whole sector 12 was disabled due to TCD (trigger cable issue)
After the access run 21038013 Tonko reported
The problem is under the poletip somewhere and nothing
we tried to do made it go away.
The problem is 1 single bit of the TCD trigger cable which
was always "0" in December (so we got around it by
using a different bit as the "trigger" pulse) but now it
is always a "1" which causes the RDOs to be "triggered"
all the time. There seems to be some sort of cable
disconnect or receiver chip malfunction.
However, I can reprogram the iTPC firmware to simply
ignore this bit on that Sector and it should work OK.
Unfortunately, I can't do this for the TPX (outer sector)
because I don't have the firmware tools anymore (15 years old).
So for the weekend we should continue as we are, without
Sector 12 altogether. I'm assuming I won't have ~2hrs alone with
the system to play with and get it all hacked-up and somewhat
recovered.
1/29/2020
sector 8-2 could not recycle; fixed by disabling one FEE
Runs w/o FEE are 21029027 to 21030010
1/28/2020
Sector 10-4 summary from Tonko's tpc log
-
itpc10-4 power problems continue
-
the board is OK until the firmware powers up the FEEs. At this point the RDO (or PS?) loses power. Could be a shorted FEE? Hm, nothing I can do…
-
OTOH this board was flickering for a while now so perhaps it’s the PS
-
⇒ need to check PS!
-
-
was 1 bad fuse at the PS and perhaps 2 others as well
-
swapped all 3 fuses, now all OK [8 Jan]
-
but crashed again with the same PS symptoms few hours later!
-
left the PS off for a few days, tried again but nada…
-
-
re-checked fuses on 22 Jan but the fuses are OK -- we’ll check again…
-
⅓ leads on the PS are not connected to the RDO
-
Bob increased the voltage so we can now boot
-
special firmware which doesn’t power-up the FEEs is installed
-
we can work without ~2 FEEs
-
-
1/09/20
The sector 10-4 only worked for a short time (few hours)
runs 008023-008034 (few cosmic runs + one data run
1/08/2020
Tonko:
Bob Scheetz found a bad fuse on the power supply and
exchanged it.
iTPC S10-4 is now working and also unmasked.
One fuse was blown, but others looked flacky, currents are now stable.
last run where bad was 21008016
1/06/2020
Tonko:
I looked at the failed & masked iTPC RDO iS10-4 in detail.
The problem is with the power, possibly the power supply. We would need an access to take a better look at the PS to see where the problem lies.
1/05/2010 fixed by run 21005019
msg from Tonko
please unmask ITPC Sector 13, RDO 2 on the next run.
A FEE died and I masked it out.
1/04/2020 sector10 itpc RDO 4
caused problems in 21004005 and then in 007 with 7 auto eboot during run, after which it was masked out.
1/03/2020
sector 13-2 out as of run 21003011
sun 12/22/19
For the runs between 2:44 and 8:15 today (20356005-20356018), there is some chance that the data from sector 12 is wrong (comes from a different event). During this time we were running with 4095 tokens, but half of them were indistinguishable to sector 12. There were many errors / overruns during these runs, and it is difficult to know whether the events that were built contain data from the correct token or from a indistinguishable token.
12/20/2019 sector 12 issue
Tonko msg:-
The entire Sector 12 sees bad/corrupt trigger data.
But the clock on that same cable is OK so it's not a total cable disconnect.
The cables get fanned out to 24 sectors in one board/system
(called "TDBm") which is my prime suspect right now.
1) I masked out the TPX RDOs which end up being readout
on a PC called "tpx30" so we can include "tpx30" in the runs.
This will also re-enable 2 outmost RDOs from the adjacent sector 11.
2) I powercycled the TDBm fanout but this made no difference.
3) Next suspect is the cable connections on the fanout,
perhaps the connector/cable got dislodged (it happened).
But for this I need tech help (Bob Scheetz preferably).
I sent him email and I'll call him in the morning.
4) If it is not a simple bad connection it could be a dead
PECL driver chip in that fanout (it also happened) so
we need to change it or swap in a spare. This also needs
to wait until the morning.
5) In the worst case it can be some sort of cable disconnect
at the poletip so, well, you know what that means :-).
But at this stage I find it unlikely.
For now please leave the Run Control components "tpx12"
and "itpc12" out of the runs.
-- report from shift earlier
We were trying to take a pedestal_tcd_only data after the LEReC was done. However, it shown that trigger is 100% from the DAQ monitoring and the number of event
token by detectors are all 0. We called DAQ expert Jeff. He took the control and did some tests, he mentioned that the TPC sector 12
(TPX 12, 30 and iTPC 12) are busy during the data token. There sectors will make it hard to take any data, also he do not think this is a software issue.
Currently, the suggestion is we need to mask out these sectors from run control during tonight’s runs.
353035 sector 12 and 2 RDO from 11 (TPX computer 30)
354003 - 354006 all of 12 out (planned to be fixed at 2pm Friday)
12/18/19 Shift e-log
Run 20352010 - TPC inter Cage 1 current red alert after beam dump.
Run 20352016 - TPX died, TPX28 masked out, try restarting the run
Run 20352018 - 6:00 am production_11p5GeV_2020, TRG+DAQ+TPX+iTPC+BTOW+TOF+GMT+L4, include TPX28
12/17/19
Run 20351004 - We managed to start the run by clicking in and out iTPC, and this run contains ETOF, BBC 100kHz, minbias 160 Hz
production_11p5GeV_2020, TRG+DAQ+TPX+iTPC+BTOW+TOF+ETOF+GMT+L4
------------------------------------
Tonko: Nah, clicking in/out doesn't do anything. But I fixed the issue in the background: power-cycled RDO iTPC iS22-4 and restarted DAQ.
12/10/19 Flemming
I started up my QA test of file. Overall things look good. The statistics is for iinner sectors only. The particular run 344017 had Sector 20 RDO-3 masked out (15 FEE) . Apart from that there are
2 single FEEs masked out S12-FEE-47 S8 FEE-33. There are a total of 198 single bad channels with a total of 1259.
I noted that the charge (ADC) plot for TPX sector 4 seems to have an even-odd issue. This is not seen in the JEVP plot since these have a binning of 4.
Only sector 4 shows this. Will check to see what part of the sector shows this. False alarm - it all comes from a single hot pad in sector 4 TPX
12/10/19
7:43 tonko
Unmasked iTPC S20-3. The problem is in the trigger interface of the board and is intermittent. There seems to be a bad connection and I think is is due to the temperature and once the board warms up it starts to work fine. Now that we are in relatively stable run conditions I'd like to see how it behaves over the course of a day, e.g.
12/8/2019
Run 20342030 - Upon instruction from Tonko, we rebooted the iTPC DAQ computer. The iTPC20 in the component tree was back, and we unmasked iTPC sector 20 RDO3. But we couldn't start the run (the run was in configuring mode and iTPC20 was waiting for several minutes). We did another reboot of the DAQ computer. And after that, we noticed the iTPC20 RDO3 LED light shows still grey, we powercycled the FEE on SC. The run eventually got started.
If later on this iTPC sector 20 RDO3 causes problem, mask it out from RC and leave a note in SL.
It is now masked off (Rdo 3)
12/4/2019
The pole tip was opened and the cable was replaced for 11.5 PSU . It is now operational
Tested the 'bad cable' Bob Scheetz reported
So after improving my test procedure, I do see a problem with that cable we removed. When I use a pigtail connector with the meter clipped to the leads and make a fully latched connection I don’t have conductivity , I need to put side pressure on the connector to make contact, need to explore this more. Some of my other spares have similar problems. Not Good.
12/2/2019 (11:15 Mike C.
Replaced two fuses in S11.5 PSU, reconnected cable. Left S11.5 PSU "OFF", one conductor open in cable will cause fuses to blow until cable is replaced.
12/2/2019
6:14 (tonko note)
1) itpc20-3 again has problems with the TCD interface. Powercycled and now it's OK. Unmasked. However, this will probably happen again. Let's see.
2) itpc21-1 dead FEE on port #8. Doesn't look recoverable. Masked the particular FEE and unmasked the RDO.
11/29/2019 4:34 (tonko from e-log)
Some fixes to TPX/iTPC electronics:
1) itpc20-3 has issues with token overruns, oddly. Now it works so I unmasked it but I will keep an eye on it because the problem will likely return.
2) tpx05-3 masked 2 FEEs on a bad RDO bus. Magnet related? RDO unmasked.
3) tpx17-3 masked 2 FEEs on a bad RDO bus. Magnet related? RDO unmasked.
4) itpc08-2 masked 1 FEE. The FEE seems to come and go causing too many recoveries. It looks like it's on the RDO end (port #6) because we already changed that FEE.
5) tpx11-4 and tpx11-5 are still down due to a power supply failure. Need to wait for Monday for e.g. Mike to take a look and swap it.
Groups:
- videbaks's blog
- Login or register to post comments