Update 12.03.2018 -- Run 9 pp: Response Comparison For Different Priors
By definition, the response matrix should be more or less independent of the prior used to train it. So is that actually true in my set-up? Below are some plots to compare the response matrices for a few different priors.
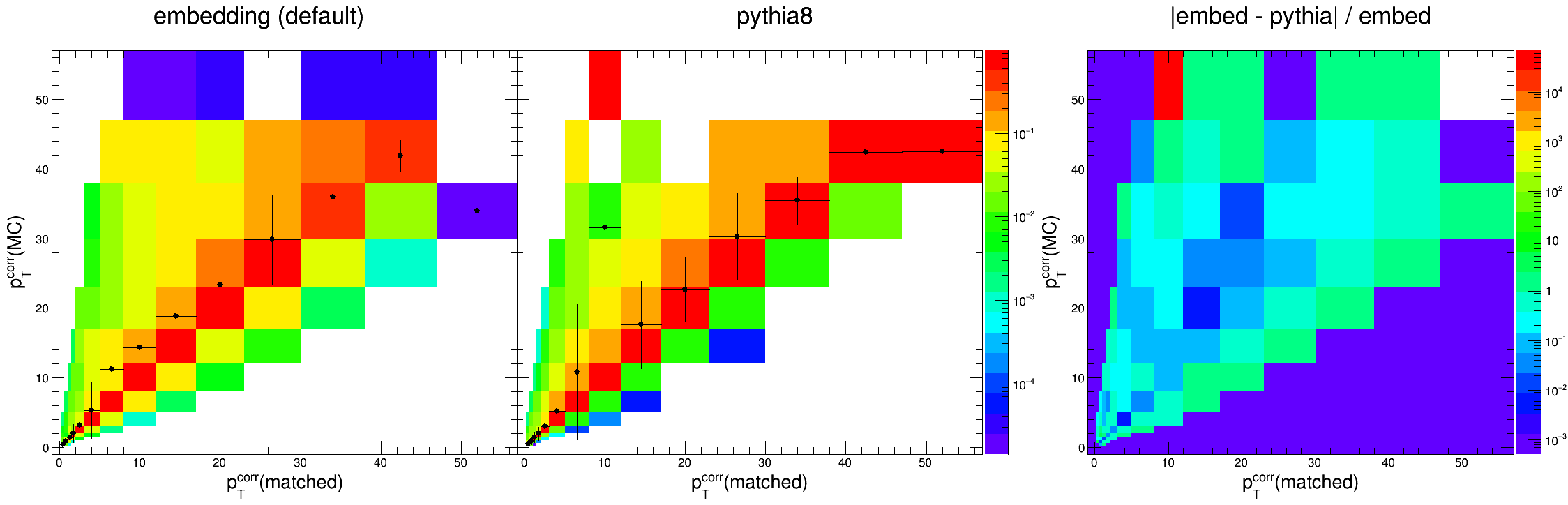
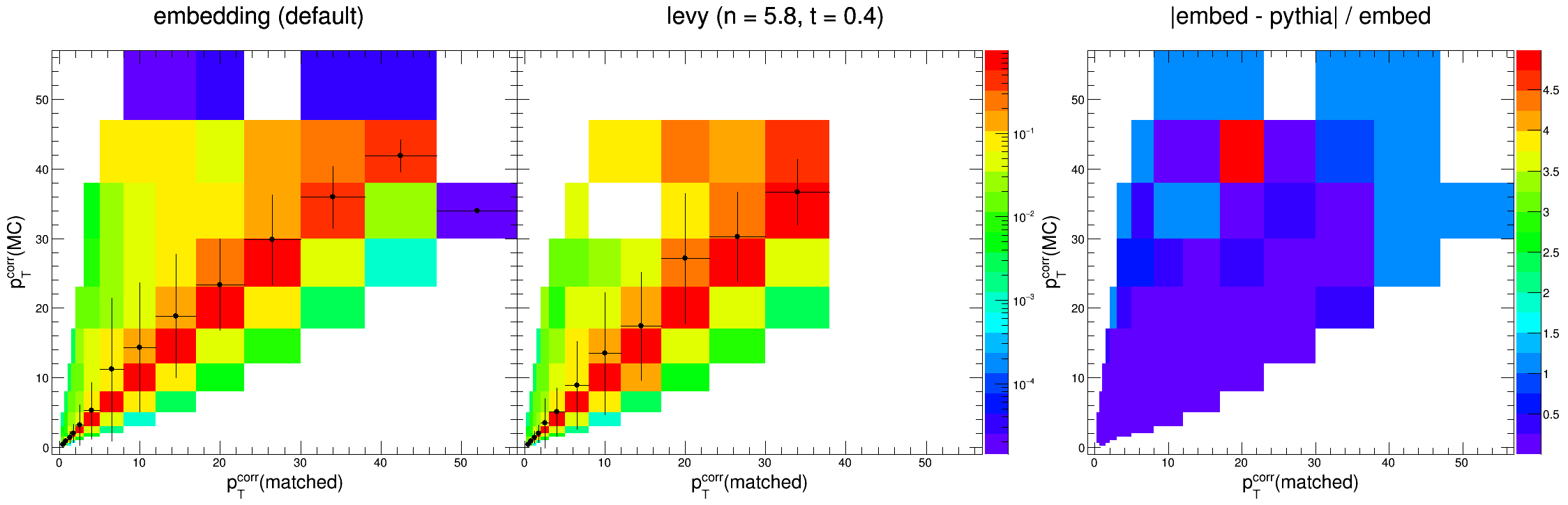

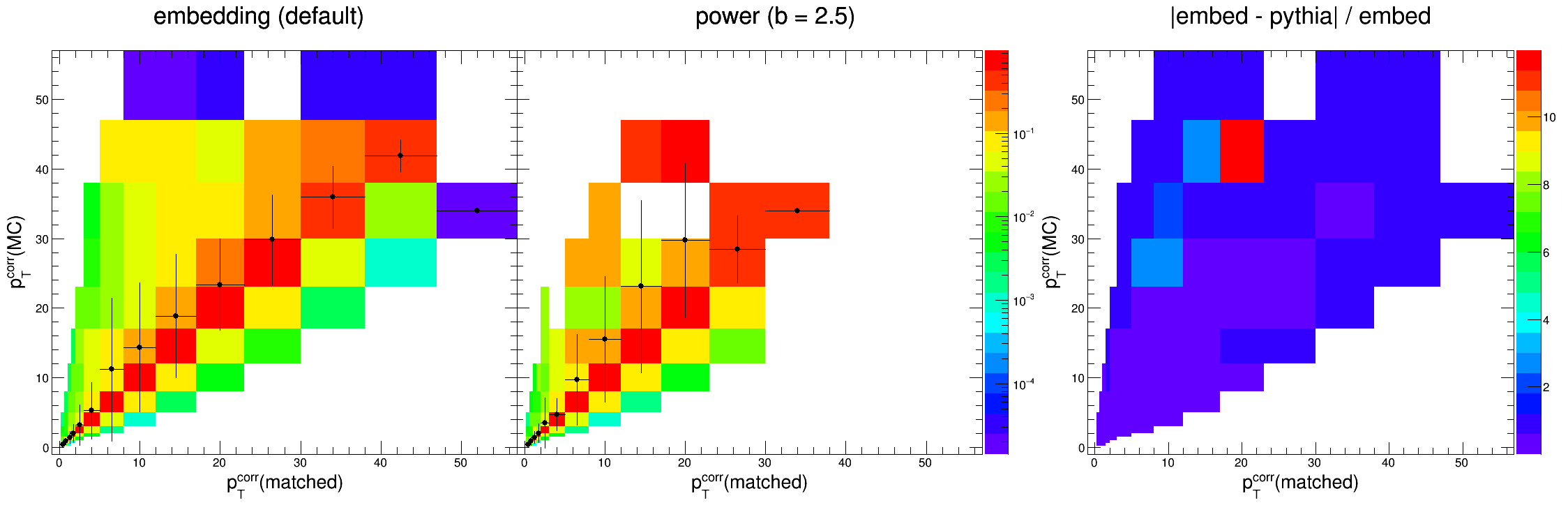
As you might be able to tell, within our kinematic region (detector-level pTjet = 0.2 - 30 GeV/c) they are indeed consistent. The plots below overlay the profiles of the response matrices for easier comparison.
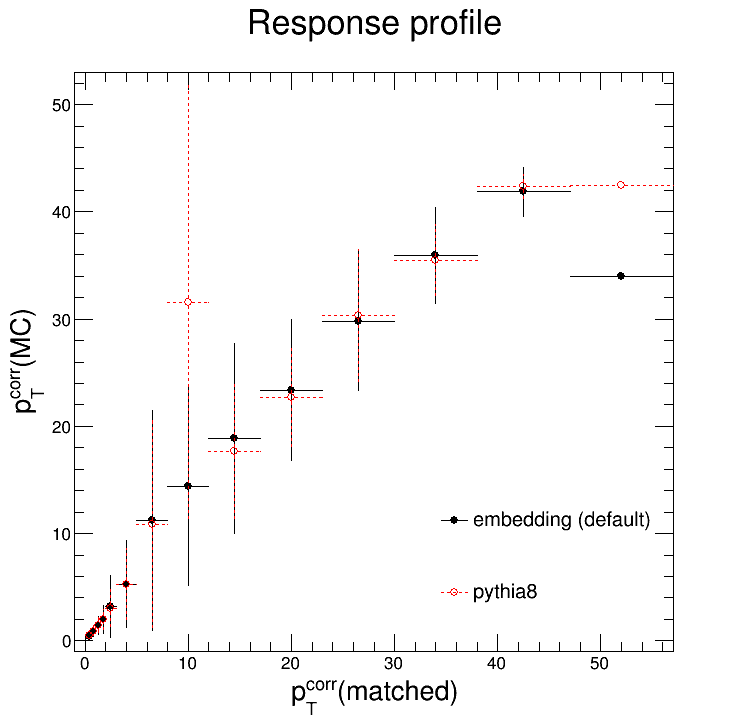

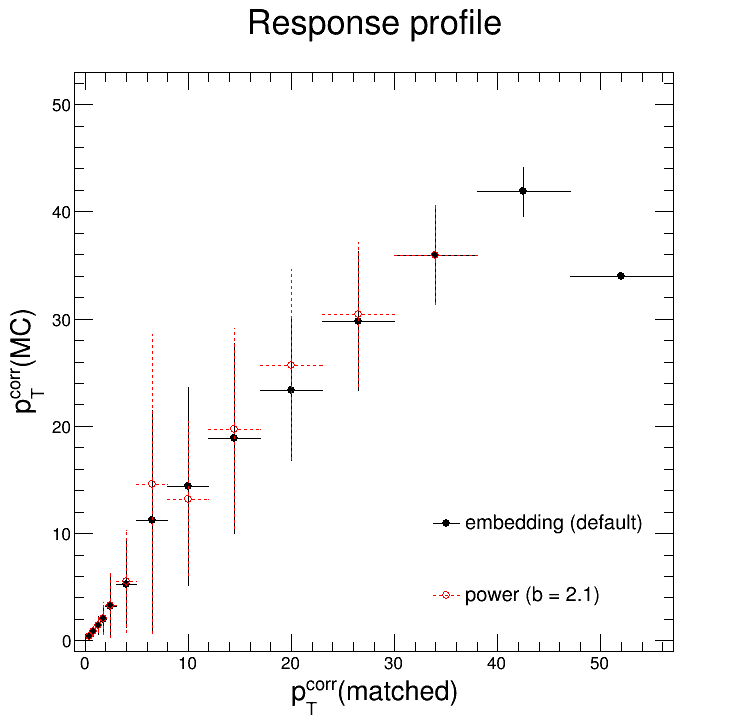
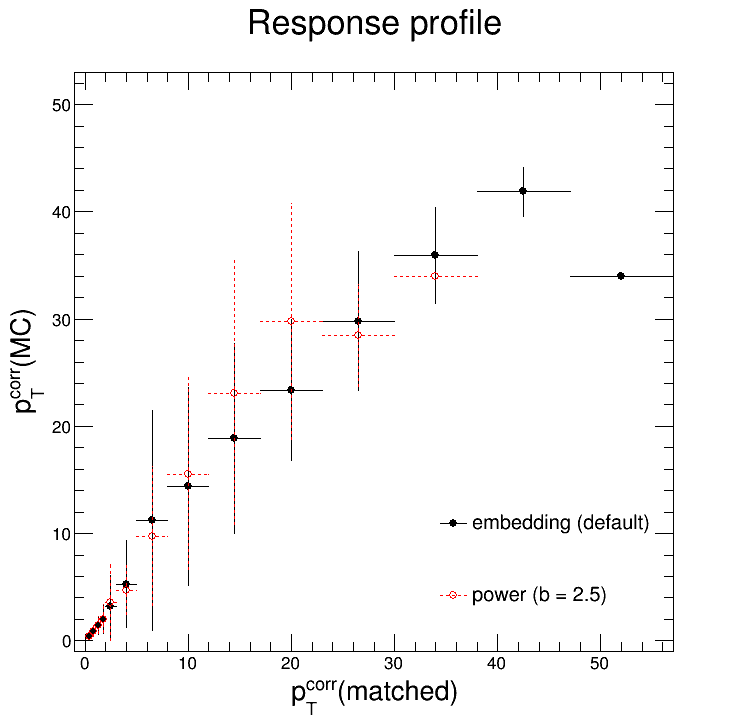
So this is all well and good. But you, dear reader, might remember that there were some noticeable differences in the unfolding solutions for different priors:
https://drupal.star.bnl.gov/STAR/blog/dmawxc/update-11162018-run-9-pp-prior-check
So if the response matrices are roughly the same, what's driving those differences? Likely the jet-matching efficiency! So how do those compare?
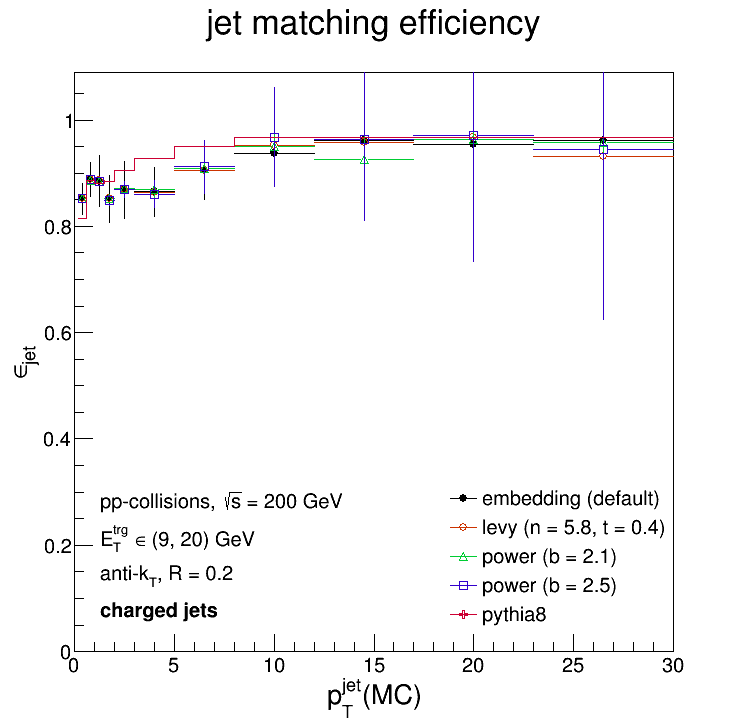

(I apologize: I inadvertently removed the statistical error bars from the Pythia8 efficiency.) As you can see, the efficiencies are roughly the same aside from the Pythia8 prior which has a substantial excess in the region of pTjet = 2 - 10 GeV/c or so...
- dmawxc's blog
- Login or register to post comments