Update 08.02.2019 -- Run 9 pp: Pythia8 vs. Pythia6 Response Matrices With Finer Binning
Previously, I checked to see if the discrepancy between the Pythia8 and Pythia6 responses was due to the efficiencies or the response matrix. And it definitely looked like something was up with the Pythia8 response:
Yesterday, I went over the code that calculates and normalizes the Pythia8 response and couldn't find anything wrong... So where could the issue be? There's definitely something wrong with the Pythia8 response, but the calculation/normalization process looks totally fine.
However, today I compared the two response matrices using a finer binning and a wider range. And I think I found the problem:

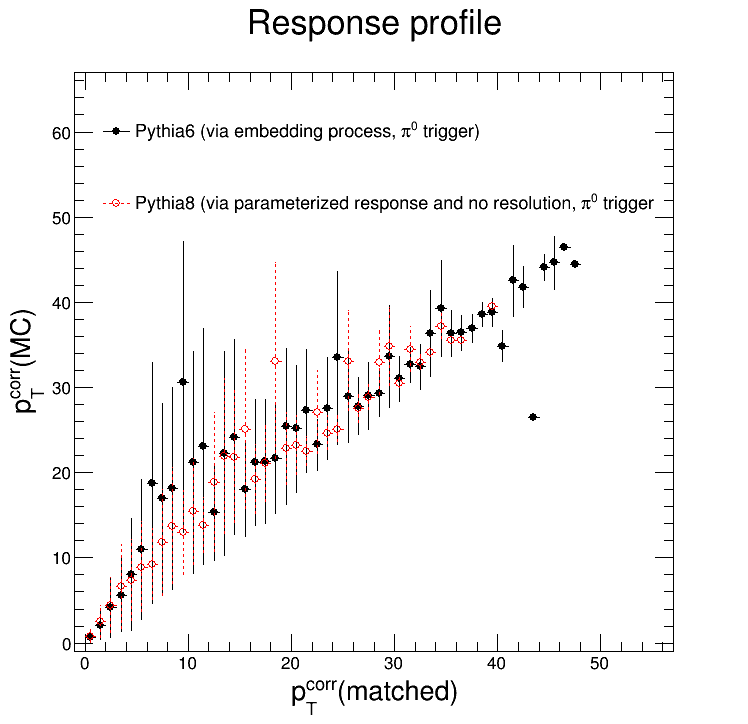
The Pythia8 response matrix only goes out to about pTjet = 20 GeV/c. And today Nihar also noticed something similar: using a set of Pythia data we generated with pThat = (5, 15) GeV/c, the response matrix only gets out to ~20 GeV/c as well.
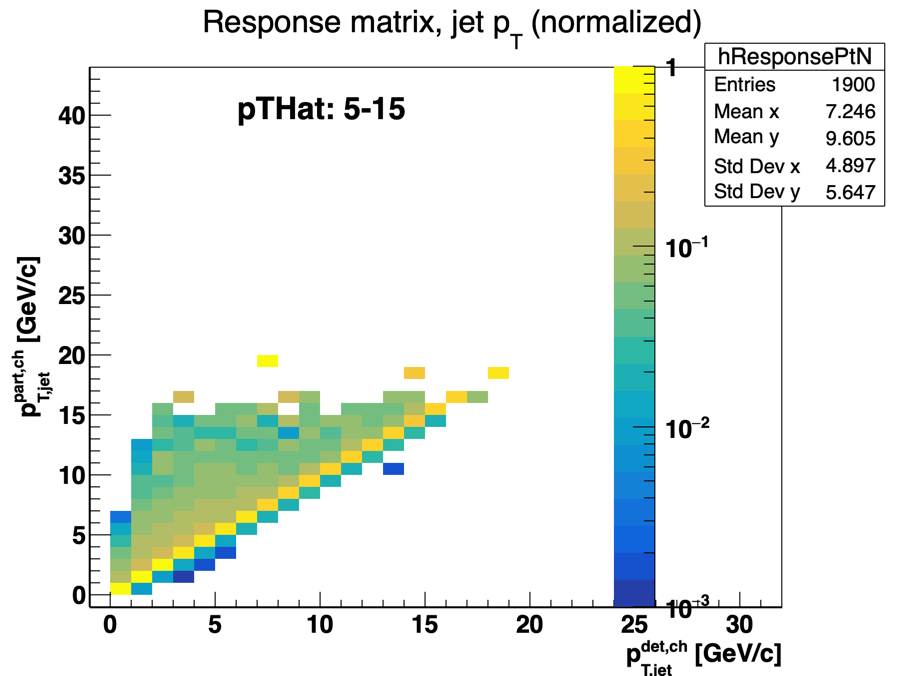
This explains things. Since the matrix is normalized to be unitary, the integral of the data to be unfolded will be preserved throughout the unfolding process. In the Pythia6 case, that means the integral will be spread out over a larger range (0 ~ 30 GeV/c or so) and thus the unfolded spectrum will appear softer. The Pythia8 data I've been using to train the response matrix was made with the requirement pThat > 4 GeV/c. The pThat spectrum is steeply falling, so we're going to be dominated by low pThat events and thus have a limited reach in pTjet.
To confirm this, we could look at the response matrix for higher bins of pThat (e.g. 15 - 20 GeV/c or more) and see how that affects the reach of the matrix. Thankfully, we were already planning on doing that for studies in the AuAu analysis.
- dmawxc's blog
- Login or register to post comments